Unicode
유니코드는 다양한 언어와 문자를 컴퓨터에서 표현하기 위해 탄생했습니다.
예를 들어 영어와 같은 알파벳 기반 언어의 문자는 아스키(ASCII)라는 문자 인코딩을 통해 1 byte(8 bit)만을 사용해 표현할 수 있지만, 다른 언어의 문자들은 1 byte로 표현할 수 없었습니다.
이로 인해 언어 간 데이터 교환, 다국어 텍스트 처리, 국제화 및 로컬라이제이션 작업 등에서 어려움이 발생했습니다.
전 세계의 다양한 언어와 문자를 효과적으로 표현하고 처리하기 위해서는 통일된 표준이 필요했고 이런 필요성을 해결하기 위해 유니코드가 등장하게 되었습니다.
1991년 처음으로 유니코드는 발표되었고 초기에는 16 bit로 최대 65,536개의 문자를 표현할 수 있는 UCS-2라는 인코딩 방식을 사용했습니다.
그러나 이후에 유니코드는 계속해서 확장되어 현재는 수천 개의 문자를 지원하는 UTF-8, UTF-16, UTF-32 등 다양한 인코딩 방식을 가지고 있습니다.
즉 국제적으로 모든 언어를 표시할 수 있는 표준 코드가 유니코드입니다.
더 자세한 내용은 유니코드 공식 사이트를 참고 부탁 드립니다.
Encoding
인코딩은 컴퓨터에서 문자와 기호를 표현하기 위해 문자를 이진 데이터로 변환하는 과정이며 문자와 이진 데이터 간의 매핑 규칙을 정의하는 방법입니다.
매핑 규칙은 어떤 문자가 어떤 이진 데이터로 표현되는지를 정의하며 문자 집합을 bit 패턴으로 매핑하는 방법을 제공합니다.
- 가변 너비 인코딩(Variable-Width Encoding): 가변 너비 인코딩은 문자의 범위와 특정 문자에 대한 정보를 보다 효율적으로 표현하기 위해 문자에 따라 필요한 비트 수를 가변적으로 조절합니다.
- 고정 길이 인코딩(Fixed-Length Encoding): 고정 길이 인코딩은 문자마다 동일한 비트 수를 할당하여 표현하는 방식입니다. 문자마다 동일한 공간 크기를 사용하므로 처리가 비교적 간단하고 빠르지만 저장 공간을 많이 차지합니다.
UTF(Unicode Transformation Format)
UTF는 유니코드 문자를 이진 데이터로 변환하는 인코딩 방식입니다.
유니코드는 전 세계의 모든 문자와 기호를 표현하기 위한 표준이며, UTF는 이 표준에 따라 문자를 효율적으로 저장하고 전송하기 위해 설계된 다양한 인코딩 형식을 지칭합니다.
유니코드 영역은 각 언어별 유니코드 범위를 저장한 표입니다.
UTF-8
UTF-8은 하나의 문자를 나타내기 위해 1 바이트에서 4 바이트까지를 가변 너비 인코딩 방식을 사용합니다.
ASCII 인코딩과 완벽하게 호환되며 ASCII 문자는 1 바이트로 표현하고 유니코드 문자는 추가 바이트로 표현됩니다.
또한 유니코드의 범위에 따라 UTF-8 바이트 용량이 정해지며 아래와 같은 표로 정의해 놓았습니다.
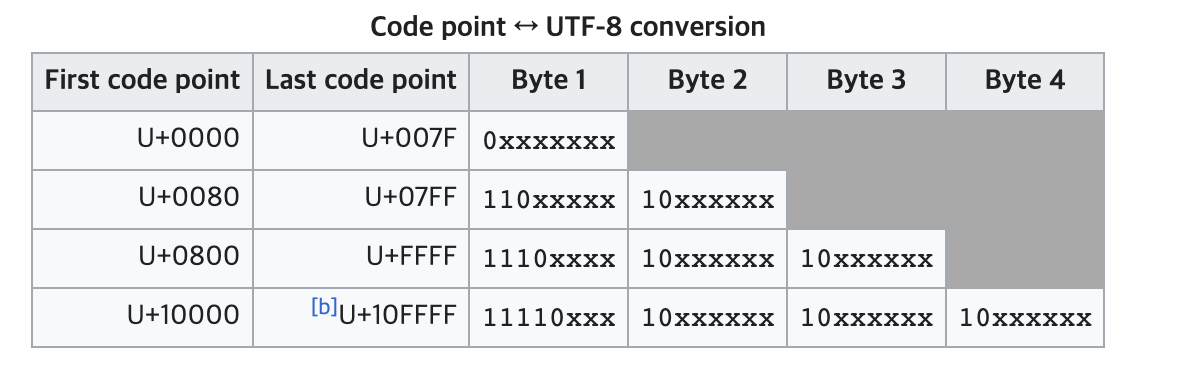
즉 첫번째 바이트에서 시작되는 비트가 무엇인지에 따라서 몇 바이트까지 읽을 것인지 결정합니다.
- 0xxxxxxx: 첫번째 바이트가 0으로 시작한다면 0 이외의 7 비트를 ASCII로 인식합니다. 숫자와 알파벳이 해당됩니다.
- 110xxxxx 10xxxxxx: 두번째 바이트까지 읽어서 하나의 문자로 표현합니다. 아라비아 문자가 해당됩니다.
- 1110xxxx 10xxxxxx 10xxxxxx: 세번째 바이트까지 읽어서 하나의 문자로 표현합니다. 한글, 한자가 해당됩니다.
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx: 네번째 바이트까지 읽어서 하나의 문자로 표현합니다. 어려운 한자와 같은 문자가 해당됩니다.
UTF-16
UTF-16은 모든 문자를 16 비트(2 바이트) 또는 32 비트(4 바이트)로 인코딩하는 가변 너비 인코딩 방식을 사용합니다.
기본 다국어 평면(BMP: Basic Multilingual Plane)에 속하는 문자는 2 바이트로 표현됩니다.
BMP는 유니코드의 0부터 0xFFFF까지의 코드 포인트를 포함하며 유니코드로는 U+0000에서 U+FFFF에 놓인 문자들을 담고 있습니다.
BMP에 속하지 않는 문자는 즉 2바이트로 표현할 수 없는 나머지 문자는 2개의 코드 단위로 표현 되며 4 바이트로 표현됩니다.
이를 위해 UTF-16은 서로게이트 페어(Surrogate Pair)라는 코드 단위 조합을 사용하며 상위 서로게이트(Surrogate High)와 하위 서로게이트(Surrogate Low)라는 두 개의 코드 단위로 구성됩니다.
서로게이트 페어는 다른 범위의 코드 포인트에 할당되어 BMP를 벗어나는 문자들을 표현합니다.
UTF-32
UTF-32는 32 비트(4 바이트) 단위로 문자를 인코딩하는 고정 길이 인코딩 방식을 사용합니다.
모든 문자가 4 바이트로 고정되게 표현되므로 가변 길이의 부호를 해석할 필요가 없어 처리가 단순하지만 1 바이트로 처리 가능한 문자도 4 바이트를 할당하기 때문에 공간 사용량이 증가합니다.
오탈자 및 오류 내용을 댓글 또는 메일로 알려주시면, 검토 후 조치하겠습니다.