정규화(Normalization)
정규화란 관계형 데이터베이스의 데이터 모델 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 의미하며 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것을 목표로 합니다.
정규화는 테이블 간의 종속성을 분석하고 데이터를 여러 테이블로 분할하여 중복을 줄이는데 중점을 두고있으며 하나의 테이블에서의 데이터의 삽입, 삭제, 변경이 정의된 관계들로 인하여 데이터베이스의 나머지 부분들로 전파되게 하는 것입니다.
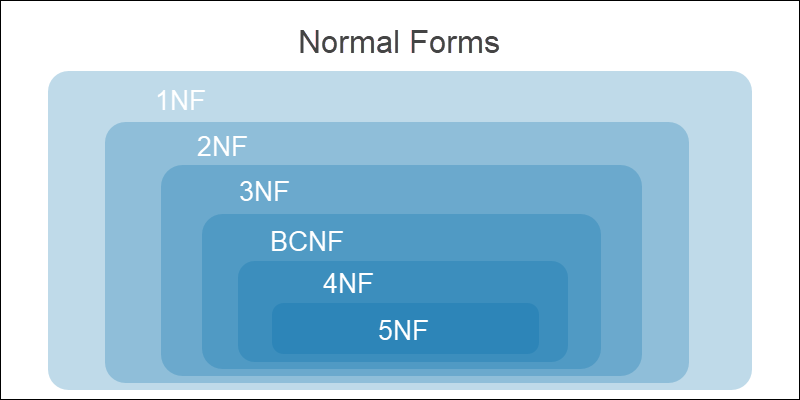
또한 정규화는 여러 단계로 정의되어 있는 정규형(Normal Form)이라는 규칙을 따라 데이터 모델의 정규화가 이루어지는데 각 단계는 아래와 같습니다.
먼저 다음과 같은 정규화 되지 않은 테이블이 존재한다고 가정하겠습니다.
| 관리자 아이디 | 관리자 이름 | 영역 | 직원 아이디 | 직원 이름 | 섹터 아이디 | 섹터 이름 |
|---|---|---|---|---|---|---|
| 1 | 민수 | 동쪽 | 1, 2 | 데이비드, 유진 | 4, 3 | 금융, IT |
| 2 | 영희 | 서쪽 | 3, 4, 5 | 조지, 헨리, 잉그리드 | 2, 1, 4 | 보안, 행정, 재무 |
| 3 | 철수 | 북쪽 | 6, 7 | 제임스, 케이티 | 1, 4 | 행정, 재정 |
제1정규형(1NF)
제1정규화란 데이터의 각 컬럼은 원자적인 값(Atomic value)을 갖도록 분해하는 것입니다.
즉 한 컬럼에 여러 값을 포함하지 않아야 하고 각 컬럼의 값은 단일 값을 가지며 중복된 데이터가 없어야 합니다.
목록으로 저장된 영역, 직원 이름, 섹터 아이디에 대한 제1정규형하여 데이터를 분해한 테이블은 아래와 같습니다.
| 관리자 아이디 | 관리자 이름 | 영역 | 직원 아이디 | 직원 이름 | 섹터 아이디 | 섹터 이름 |
|---|---|---|---|---|---|---|
| 1 | 민수 | 동쪽 | 1 | 데이비드 | 4 | 금융 |
| 1 | 민수 | 동쪽 | 2 | 유진 | 3 | IT |
| 2 | 영희 | 서쪽 | 3 | 조지 | 2 | 보안 |
| 2 | 영희 | 서쪽 | 4 | 헨리 | 1 | 행정 |
| 2 | 영희 | 서쪽 | 5 | 잉그리드 | 4 | 재무 |
| 3 | 철수 | 북쪽 | 6 | 제임스 | 1 | 행정 |
| 3 | 철수 | 북쪽 | 7 | 케이티 | 4 | 재정 |
해당 테이블은 제1정규형을 만족합니다.
제2정규형(2NF)
제2정규형이란 제1정규화를 진행한 테이블에 모든 비주요 속성이 주요 속성에 대해 완전 함수 의존성을 가지도록 분해하는 것입니다.
즉 테이블의 각 행은 기본 키에 종속되게 분해해야 합니다.
관리자
| 관리자 아이디 | 관리자 이름 | 영역 |
|---|---|---|
| 1 | 민수 | 동쪽 |
| 2 | 영희 | 서쪽 |
| 3 | 철수 | 북쪽 |
직원
| 직원 아이디 | 직원 이름 | 관리자 아이디 | 섹터 아이디 | 섹터 이름 |
|---|---|---|---|---|
| 1 | 데이비드 | 1 | 4 | 금융 |
| 2 | 유진 | 1 | 3 | IT |
| 3 | 조지 | 2 | 2 | 보안 |
| 4 | 헨리 | 2 | 1 | 행정 |
| 5 | 잉그리드 | 2 | 4 | 재무 |
| 6 | 제임스 | 3 | 1 | 행정 |
| 7 | 케이티 | 3 | 4 | 금융 |
해당 두 테이블은 관리자 아이디와 직원 아이디를 기본 키로 가지는 두 개의 테이블로 제2정규형을 만족합니다.
제3정규형(3NF)
제3정규형은 제2정규형을 진행한 테이블에 대해 테이블 내의 모든 컬럼이 기본 키에 대해 이행적 함수 종속되지 않도록 분해하는 것입니다.
이행적 함수 종속이란 A -> B 이고 B -> A일 때 A -> C를 만족하는 관계를 의미합니다.
즉 어떤 비주요 컬럼도 다른 비주요 컬럼에 의존해서는 안 된다는 것을 의미하며 의존성이 존재한다면 해당 컬럼을 분리하여 새로운 테이블로 생성되어야 합니다.
현재 직원 테이블에는 두 개의 테이블로 분해해야 하는 이행적 함수 종속성이 있습니다.
직원
| 직원 아이디 | 직원 이름 | 관리자 아이디 | 섹터 아이디 |
|---|---|---|---|
| 1 | 데이비드 | 1 | 4 |
| 2 | 유진 | 1 | 3 |
| 3 | 조지 | 2 | 2 |
| 4 | 헨리 | 2 | 1 |
| 5 | 잉그리드 | 2 | 4 |
| 6 | 제임스 | 3 | 1 |
| 7 | 케이티 | 3 | 4 |
섹터
| 섹터 아이디 | 섹터 이름 |
|---|---|
| 1 | 행정 |
| 2 | 보안 |
| 3 | IT |
| 4 | 금융 |
위 테이블은 섹터 이름이 섹터 아이디(기본 키)에 직접적으로 의존하지 않고 직원 아이디에 의존하기 때문에 제3정규형에 위반합니다.
때문에 섹터 이름이 섹터 아이디에 의존하도록 두 개의 테이블로 분해합니다.
보이스-코드 정규형(BCNF(Boyce-Codd Normal Form))
보이스-코드 정규형은 제3정규형을 보완하여 더 엄격한 조건으로 테이블은 분해하는 단계로 제3정규형을 진행한 테이블에 대해 모든 결정자가 후보 키가 되도록 분해하는 것입니다.
아래와 같이 교수와 연구 분야 대한 정보를 저장하는 테이블이 있다고 가정하겠습니다.
직원
| 직원 아이디 | 직원 이름 | 관리자 아이디 | 섹터 아이디 |
|---|---|---|---|
| 1 | 데이비드 | 1 | 4 |
| 2 | 유진 | 1 | 3 |
| 3 | 조지 | 2 | 2 |
| 4 | 헨리 | 2 | 1 |
| 5 | 잉그리드 | 2 | 4 |
| 6 | 제임스 | 3 | 1 |
| 7 | 케이티 | 3 | 4 |
섹터 아이디는 직원 아이디와 기능적 의존성이 존재하기 때문에 BCNF에 위반합니다.
즉 섹터 아이디는 직원 아이디에 따라 다른 값을 가지기 때문에 연관 관계를 가지는 새로운 테이블로 분해합니다.
섹터담당
| 직원 아이디 | 섹터 아이디 |
|---|---|
| 1 | 4 |
| 2 | 3 |
| 3 | 2 |
| 4 | 1 |
| 5 | 4 |
| 6 | 1 |
| 7 | 4 |
오탈자 및 오류 내용을 댓글 또는 메일로 알려주시면, 검토 후 조치하겠습니다.
'Computer Science > Data Base' 카테고리의 다른 글
| [DB] 인덱스(Index) (1) | 2023.11.15 |
|---|---|
| [DB] Lock (2) | 2023.11.09 |
| [DB] Transaction (1) | 2023.11.02 |


